3D-televisioita on viime vuosina markkinoitu paljon ja kolmiulotteisuus on muuttunut televisioiden erityisominaisuudesta niiden perusominaisuudeksi. Myös muissa laitteissa on esiintynyt 3D-näyttöjä, kuten esimerkiksi Nintendo 3DS-pelilaitteessa ja LG Optimus 3D-puhelimessa.
Televisioissa kolmiulotteisuuden havainto mahdollistuu stereoskooppisen näytön avulla, joka näyttää vasempaan ja oikeaan silmään hiukan erilaisen kuvan. Tämä on yleensä toteutettu stereoskooppisen näytön kanssa yhteensopivilla laseilla, jotka ohjaavat eri kuvat oikeaan ja vasempaan silmään. Mukana kannettavassa laitteessa erillisten stereolasien käyttäminen olisi hankalaa, joten niissä käytetään autostereoskooppista näyttöä, joka muodostaa kolmiulotteisen kuvan ilman tarvetta laseille. Autostereoskooppisia näyttöjä on kokeiltu eri laitteissa vuosien ajan, ollessani Nokia Research Centerissä tutkijana testasimme erästä ensimmäisistä 3D-kännyköistä, Sharp mova sh505i:tä. Puhelin oli myynnissä vain Japanin markkinoilla, joten sitä oli vaikea saada, mutta lopulta onnistuimme. Testasimme monia juttuja ja julkasimme aiheesta yhden artikkelinkin.
Vaikka Sharpin kännykässä oli hyviä puolia, oli siinä myös monia ongelmia. Erityisen hankalaa oli pieni katselukulma, mikä tarkoitti sitä, että kännykkää täytyi pitää hyvin tarkasti tietyssä kulmassa, jotta kolmiulotteisuusefekti näkyi. Jos sillä pelasi peliä, joka vaati näppäinten painamista, aiheutti näppäimen painaminen kännykän muutaman millimetrin liikkeen, mikä hävitti 3D-efektin. Ei ihan huippukäytettävyyttä! Toinen ongelma oli sovellusten puute. Puhelimen ensimmäisessä versiossa näppäimistön yhden näppäimen vieressä oli sininen teksti ”3D”. Kun tätä näppäintä painoi muutaman sekunnin ajan, näytölle ilmestyi parin sekunnin 3D-animaatio, jossa kaksi oravaa juoksi puussa. Muita sovelluksia ei ollut!
Erona 2000-luvun alun matkapuhelimiin nykyisin useimpia mobiililaitteita ohjataan kosketusnäytöllä, mikä saattaa stereonäyttöön yhdistettynä tuottaa yllättäviä ongelmia. Tavallisessa kosketusnäytössä kuva ja näytön pinta ovat samassa tasossa, joten jos käyttäjä painaa näytöllä olevaa kohdetta, sormi osuu kuvaan ja näyttöön samanaikaisesti. Stereonäytössä tilanne on toinen, koska stereoskooppinen kuva voi olla näytön fysikaalista pintaa kauempana tai lähempänä. Tämä on pelkkä illuusio, joka on saatu aikaan ohjaamalla eri kuvat vasempaan ja oikeaan silmään. Todellisuudessahan kuva on aina näytön pinnalla.
Kolmiulotteisuuden illuusio voi vaikuttaa merkittävästi laitteen käytettävyyteen. Jos kolmiulotteinen kohde on näytön pintaa kauempana, osuu siihen kurottuva sormi näytön pintaan ennen kuin se ehtii tavoittaa kohteen, ikäänkuin painalluksen kohteen edessä olisi lasipinta. Sormi myös peittää kohdetta, joten kolmiulotteisuuden havaitseminen voi olla vaikeampaa.
Jos kolmiulotteinen kohde taas on näytön pintaa lähempänä, sujahtaa sitä painava sormi kohteen läpi kunnes osuu kauempana olevaan näytön pintaan. Tässä tapauksessa syntyy myös syvyysvihjekonflikti: stereoskooppinen tieto kertoo, että kohde leijuu näytön pintaa lähempänä ja että sormi on sen takana näytön pinnassa. Sen sijaan käyttäjän näkökulmasta peittyneisyysvihje kertoo, että sormi on lähellä olevan kohteen päällä. Konflikti voi vaikeuttaa kolmiulotteisuuden näkemistä.
Stereoskooppisia kosketusnäyttöjä ei ole vielä paljon tutkittu, joten päätin lukea yhden uuden artikkelin aiheesta. Valkov ja kollegat tutkivat artikkelissaan, kuinka tarkasti oikeastaan voimme nähdä syvyystasoja silloin kun sormi on kuvion päällä. Asetelma toteutettiin tavallisella stereonäytöllä ja sormen liikkeitä seurasi näytön sivulle asetettu Microsoft Kinect, joka tarkkaili, koska sormi osuu näyttöön.
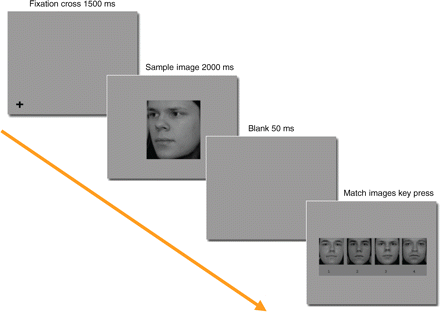
Kokeessa koehenkilö painoi sormensa näytöllä olevaan ristiin, jolloin ristin paikalle eli siis sormen alle ilmestyi neliö, jolla oli kolmiulotteinen syvyys, joka oli joko näyttöruutua kauempana tai lähempänä. Koehenkilö arvioi neliön syvyyttä pakkovalintatehtävällä: onko neliö lähempänä vai kauempana kuin ruudun pinta? Kokeessa vaihdeltiin neliön syvyyttä ja kokoa, jotta voitaisiin selvittää näköaistin herkkyys tälle. Koehenkilö näki kaiken kaikkiaan 99 kuvaa kokeen aikana.

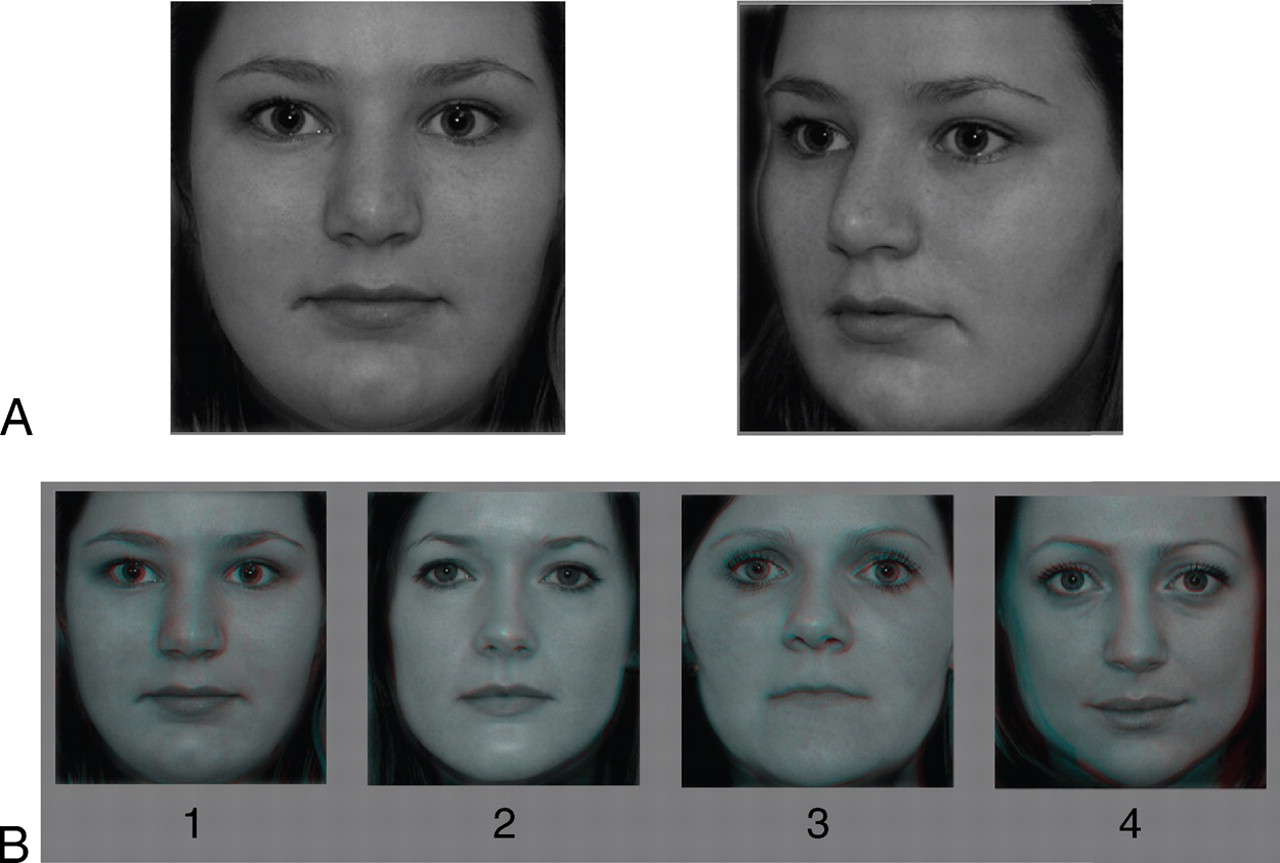
Koeasetelma Valkovin (212) artikkelista. Kun koehenkilö painoi ruudun keskelle olevaa ristiä, näytölle ilmestyi stereoskooppinen neliö. Stereoefekti näkyy valokuvassa neliön vasemmassa ja oikeassa reunassa olevina tummempina alueina.
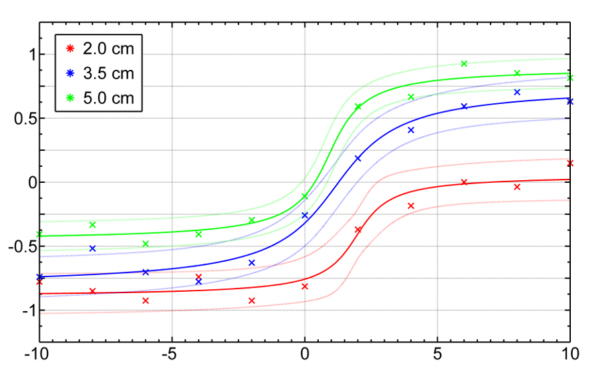
Alla olevassa tuloskuvassa kuvassa y-akseli kuvaa vastausten keskiarvoja. Kustakin ”Kauempana”-vastauksesta on tullut arvo -1 ja ”Lähempänä”-vastauksesta arvo 1. Eli mitä korkeammalla ollaan y-akselilla, sitä todennäköisemmin henkilö on vastannut ”Lähempänä” ja mitä matalammalla ollaan, sitä todennäköisemmin henkilö on vastannut ”Kauempana”.
Kuvan x-akselilla ovat neliön erilaiset syvyydet, nolla tarkoittaa näytön pintaa, nollaa pienemmät luvut näyttöä kauempana olevia neliöitä ja nollaa suuremmat luvut näytön pintaa lähempänä olevia kuvioita. Eri väriset tulospisteet taas kuvaavat eri kokoisia neliöitä. Kuvasta nähdään ensinnäkin, että koejärjestely on toiminut ihan ok: kun neliö on ollut näytön pintaa kauempana (kuvion vasen laita), se on todennäköisimmin nähty kaukana (tulospisteet miinuksella). Kun neliö on ollut näytön pintaa lähempänä, on se todennäköisimmin myös nähty lähellä.
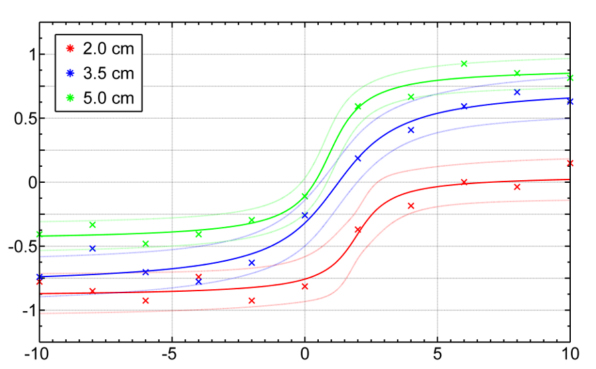
Mikä sitten on se kriittinen raja-arvo, jolla määritellään, kuinka hyvin henkilö tässä tilanteessa näkee? Se otettiin täydellisen suorituksen (1 tai -1) ja huonoimman suorituksen puolivälistä, eli niistä paikoista, joissa vastausten keskiarvo on ollut 0,5 tai -0,5 y-akselilla. Kun tätä kynnysarvoa tarkastellaan kuvassa, niin suurimmilla neliöillä (5 cm, vihreä käyrä) ihmiset alkavat luotettavasti näkemään neliön lähempänä kun sillä on syvyyttä enemmän kuin 1,67 cm. Näytön takana vihreä käyrä ei koskaan laske -0,5:n alle eli koehenkilöt eivät millään syvyyksillä pystyneet luotettavasti kertomaan neliön syvyyttä.
Jos neliö on pienempi, tulos muuttuu: koehenkilöiden kyky nähdä lähellä olevia neliöitä heikkenee, eli sininen ja punainen käyrä ovat tuloskuvan oikeassa reunassa vihreää alempana. Silti 2 cm:n koolla (punainen käyrä) ihmiset eivät ole suoriutuneet kovin hyvin: kynnys luotettavalla ”kauempana”-havainnolle on nollan positiivisella puolella, eli koehenkilöt ovat alkaneet näkemään kaukosyvyyttä jo silloin kun neliö on ollut hiukan näyttöä lähempänä. Ainoastaan 3,5 cm:n tapauksessa (sininen käyrä) henkilöt ovat huomanneet oikeaissa kohdissa, että neliö on kaukana. Käyriä katsellessa kannattaa huomata, että käyrän sijainti y-akselilla ei ole ainoa kriittinen juttu, vaan myös käyrän muoto ratkaisee, mihin kynnysarvo sijoittuu. Vaikka punainen käyrä on y-akselilla alempana kuin sininen käyrä, käyrien muodosta johtuen ainoastaan sininen käyrä leikkaa y-akselin -0,5:n arvon paikassa, jossa x-akselin arvo on miinuksen puolella, eli arvolla jotka viittaavat kaukosyvyyteen.
Pienemmän neliön tapauksessa tulos saattaisi liittyä syvyysvihjeiden ristiriitaisuuteen: pienempää neliötä on vaikeampi nähdä ruutua lähempänä kun sormi peittää siitä yhä suuremman osan.
Kauempana olevien neliöiden tulokset ovat kummallisia ja niitä on vaikea selittää: miksi suurempien neliöiden kaukosyvyys olisi hankalampaa havaita kuin pienempien? Ja miksi keskikokoisen neliön syvyys näkyy paremmin kuin pienen neliön?
Koeasetelmassa on selvästi jotakin vikaa. Ongelmia voisivat olla esimerkiksi:
1. Iso ongelma on kontrollikokeen puute, eli koetulosta ei vertailla mihinkään. Jos kokeessa olisi vertailukoeastelma, jossa olisi mitattu neliöiden näkyvyyttä ilman sormea, olisi sormen heikentävä vaikutus helpompi arvioida vertailemalla noiden kokeiden tuloksia. Nyt on mahdotonta sanoa, kuinka suuri osa tuloksesta johtuu esimerkiksi näytön laadusta tai koekuvana käytetyn neliön ominaisuuksista.
2. Kynnysarvoissa on tunnetusti paljon yksilöllistä vaihtelua. Koska näissä koetuloksissa oli laskettu kynnysten keskiarvot, voi noiden keskiarvokäyrien alle piiloutua hyvinkin paljon toisistaan poikkeavia tuloksia. Tulosten yksilöllinen vaihtelu voi liittyä moniin asioihin, esimerkiksi henkilön persoonallisuuteen: joku henkilö voi olla todella suurpiirteinen ja vastata esimerkiksi ”Lähempänä” vaikka ei olisikaan kovin varma vastauksestaan. Hyvin pikkutarkka ihminen taas on paljon tarkempi vastauksissaan ja ei vastaa ”Lähempänä” muuta kuin sellaisissa tapauksissa, että on täysin varma vastauksestaan. Jos jompikumpi vaihtoehto tässä kokeessa on ollut toista huomattavasti vaikeampi, saattaa pikkutarkoilla ja suurpiirteisillä vastaajilla tulla hyvin erilaisia käyriä. Yksilöllisten erojen poissulkemiseksi kannattaisi hyödyntää signaalindetektioteoriaa ja laskea tuloksista d’ , jossa oikeat ja väärät vastaukset suhteutetaan toisiinsa ja henkilöiden erilaiset kriteeritasot eivät vaikuta tulokseen.
3. Olen myös ihmeissäni korkeista arvoista, joita stereosyvyyden havaitsemiseksi vaaditaan tässä kokeessa. Koetulokset on hiukan hassusti ilmaistu senttimetreinä, kun yleensä tapana on ilmaista tulokset näkökulman asteina. Jos tulokset muuntaa näkökulman asteiksi, kynnysarvo stereosyvyyden näkemiselle kokeessa on 0,1 – 0,34 näkökulman astetta, mikä on valtavan suuri arvo. Tämä on aika eri arvo kuin tarkimmat mitatut ihmisen stereokynnykset, jotka ovat noin 0,00056 näkökulman astetta!
Ero johtunee ainakin siitä, että koeasetelmassa näytöllä oli ainoastaan yksi kuva. Stereosyvyyden havaitseminen perustuu kuvioiden suhteellisen syvyyden arvioinnille ja yksittäisten, muista erillään olevien kuvioiden arviointi on todella vaikeaa. Sormi on toiminut tässä kokeessa jonkinlaisena vertailukohtana, mutta se ei selvästikään ole riittänyt. Aika harvoin käyttöliittymässäkään on ainoastaan yksi painettava näppäin eikä mitään muuta.
Johtopäätökset
Tässä artikkelissa kysytään oikeita kysymyksiä, mutta toteutus jää hiukan puutteelliseksi. Tuloksia ei voi käyttää ohjeena stereoskooppisten 3D-käyttöliittymien suunnittelussa. Selvästi jonkun pitäisi tehdä tämä koe paremmin, pitää varmaan suunnata labraan.
Lähteet
Valkov, D., Giesler, A., & Hinrichs, K. (2012). Evaluation of depth perception for touch interaction with stereoscopic rendered objects. Proceedings of the 2012 ACM International Conference on Interactive Tabletops and Surfacesurfaces, 21–30.









{kind=link}